It’s a big site, with a lot of moving pieces, but I am going to zoom out and try to start at a simplified view and then drill down one step at a time.
People write some content, and it ends up on the web
Ok, maybe not that simplified.
A repo, a build step, a storage system, and a rendering layer #
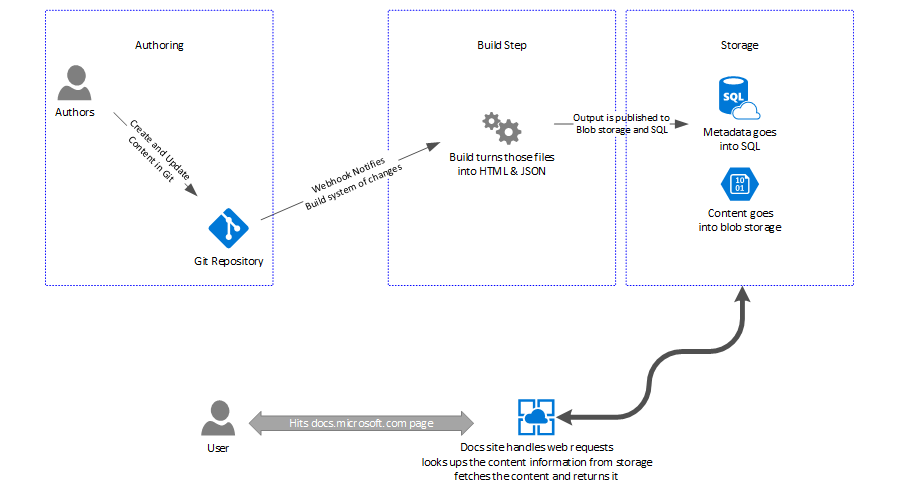
Starting with a little diagram, lets go through the different parts of the basic Docs system.
Repositories #
Content destined for Docs is authored in Git repositories, in each repository you have:
- your articles as markdown files (.md),
- a Table of Contents file (TOC), which used to be a .md file, but we now prefer YAML (.yml),
- a breadcrumb file (yml), and
- any media you need (images)
Already I’m simplifying a bit… there are lots of other files in a given content repo (check out this one, for our contributors’ guide), including some configuration and files that are not part of the content (like a readme.md or a LICENSE file), but the content is represented by the markdown and yaml files listed above. I’ll do an authoring specific discussion in a future article that will talk more about the experience of working with the content.
We ‘onboard’ a repo to Docs by creating an entry for it in our system, with a bit of info such as the URL path that this content should appear under on Docs, and setting up a webhook to let us know whenever a change is made in the repository.
The build step #
When a change is made in a repo, the webhook fires and a message ends up in a queue telling us the content needs to be rebuilt. A worker in the build system picks up this message, downloads the repo to it’s local storage and ‘builds’ the content. This involves running the DocFX process against the files in the repo, turning the markdown into html and YML into JSON. For each file, we end up with a set of metadata about it, along with the blob of content it has been turned into. The resulting set of files are ‘published’ out to our storage system known as DHS (Document Hosting System).
Storage #
DHS exposes APIs for publishing, querying and retrieving content. The end of the build step produces a set of data that has to be pushed into DHS, with metadata about each file being put into a SQL database. Each record in the database also contains a reference to a blob in storage where the actual output content is placed. We publish content into DHS for all branches of onboarded repositories, so for a given page on Docs, DHS would contain many different rows and content versions for all of the current branches that contain the source file.
Rendering #
The actual ‘docs.microsoft.com’ site is an Azure App Service. It handles some logic itself, like the Accept-Language portion of the Locale Fallback I discussed recently, but for any content request it will query the DHS layer. To make this call, the incoming URL is broken up, so a request like https://docs.microsoft.com/en-us/visualstudio/online/overview/what-is-vsonline, turns into an API request for the en-us version of online/overview/what-is-vsonline with a base path of visualstudio.
Once the content is retrieved, it is wrapped in the site chrome (so nicely illustrated by this completely correct tweet by James Pain) and the whole result is sent back to the browser.
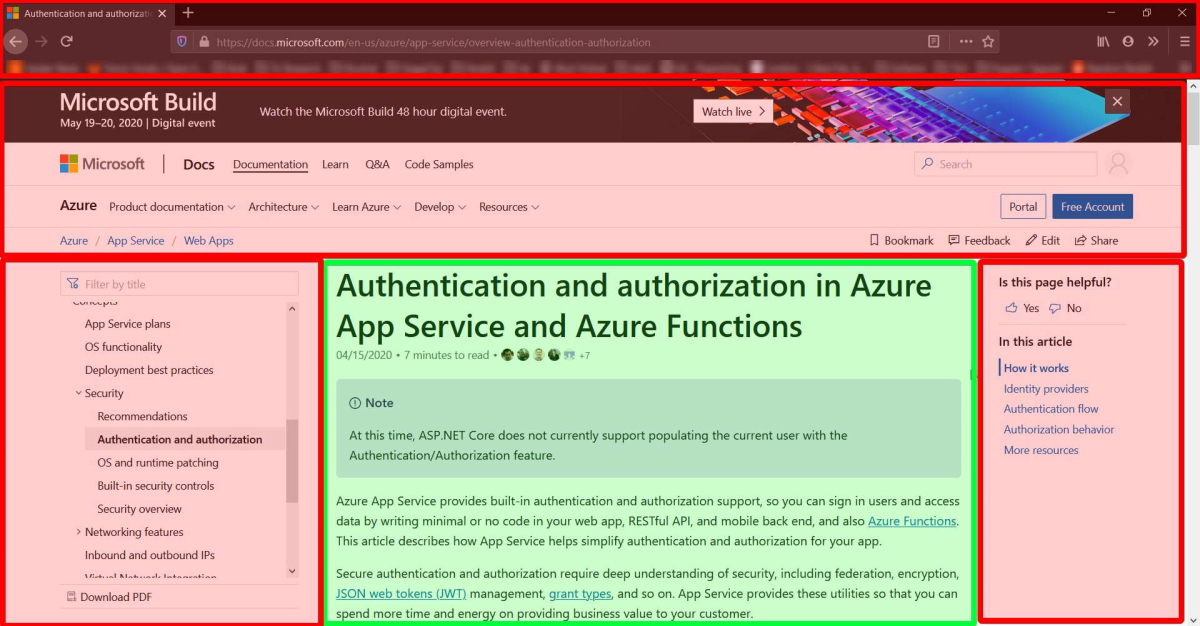
This lookup, retrieval and ‘chrome wrapping’ step doesn’t happen that often, as the final output is cached by our CDN.
Coming up next #
I mentioned that we wrap the chrome around the page in the Rendering layer, I will talk about that step, along with another set of templates that are used at build time, in the next post. Coming along soon after will be posts about how we use the CDN, the authoring workflow, a dive into our structured content (landing pages, API reference and Microsoft Learn), and then some details about how we handle private content in our repos, localization and more.